FUORI DALLA ZANZARIERA
STEP6
応答文を覚えるシステムとチャットボットインターフェイスを連携する
STEP2で作った応答文を覚えるシステムとチャットボットを連携します。
実装自体は、応答文を覚える処理以外はSTEP6と変わらないものになります。
ですが、自分だけが応答文を教えていた時と違い、WEBに公開するということは、
悪意のあるユーザの不適切な応答文への対策が必要になります。
# 必要なモジュールをインポートする
import json
import cgi
import re
# AIクラスをインポートする
from front_desk_ai import FrontDeskAi
# AIクラスをインスタンス化する
fron_desk_ai_obj = FrontDeskAi()
# 辞書情報を格納する
response_dict = fron_desk_ai_obj.readDict()
# サイト受付共通メッセージリストを格納する
common_res_list = fron_desk_ai_obj.res_message_list
# FieldStorageクラスをインスタンス化する
form = cgi.FieldStorage()
不適切な言葉も学習して弾けるのが最終的に実装したい機能ですが、今回は人の手を介すようにして回避します。
入力された言葉は、一旦、別ファイルに登録します。管理者権限を持つユーザが許可した言葉のみが、
応答文として登録するようにします。
まずは、教育コマンドを判別するために、入力文字列を検索するreモジュールをインポートします。
# 教育コマンドが先頭に指定されていた場合は、入力内容を解析する
if get_text.startswith('teach '):
teachMessage = get_text[6:]
# 入力内容(req)と応答内容(res)を検索してマッチオブジェクトを取得する。
req_obj = re.search('req ', teachMessage)
res_obj = re.search('res ', teachMessage)
# 取得したオブジェクトでreqの最終位置、resの開始位置と最終位置を取得する
if req_obj is None or res_obj is None:
responseMessage = common_res_list[5]
else:
req_end = req_obj.end()
res_start = res_obj.start()
res_end = res_obj.end()
registRequestMessage = teachMessage[req_end:res_start]
registResponseMessage = teachMessage[res_end:]
fron_desk_ai_obj.registDict(registRequestMessage, registResponseMessage)
responseMessage = common_res_list[4]
else:
# 辞書に含まれていない文字の指定の場合は、問い返す
if not responseMessage:
responseMessage = get_text + common_res_list[0] + "
" + common_res_list[1] + "
" + common_res_list[2] + "
" + common_res_list[3]
入力された文字列の先頭に「teach」がある場合に、以降の文字列を取得します。
reモジュールを利用して、「req」と「res」を検索した結果のオブジェクトを取得します。
取得したオブジェクトの開始位置と終了位置を取得し、reqとresの文字列情報を取得します。
取得した情報を登録ファイルにセットするメソッドを呼び出します。
上記を実装後に、以下のように教育コマンドを利用することで登録用ファイルに登録されるようになりました。
登録された情報は、辞書ファイルにコピペするだけで適用できるようにします。
今後の実装で、登録用ファイルの内容を辞書ファイルに移動する時にコピーした行の追加だけで出来るようにするためです。
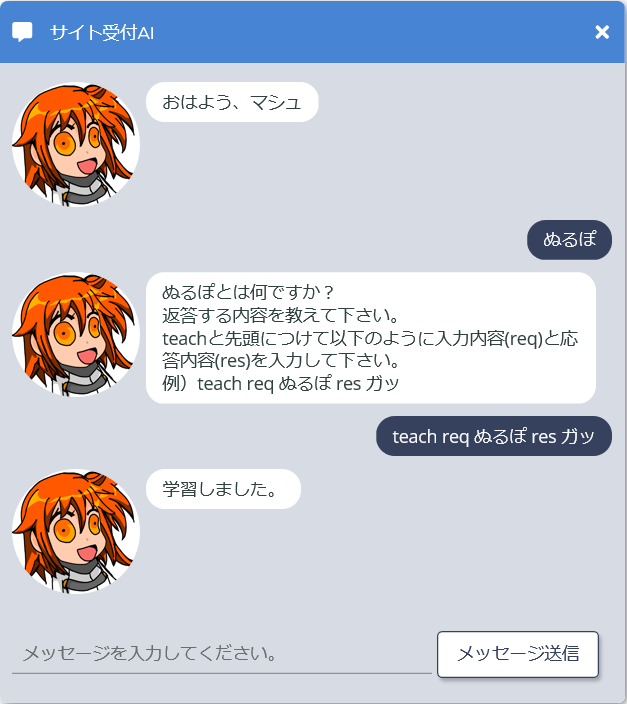
次は、ある程度の会話ができるように入力内容を解析するようにしていきます。
次回も楽しみに待っていただければ、幸いです。